Millions of animals are killed on roads everyday, all due to collisions/crashes with vehicles. The situation becomes worrisome as most animal species toggle to endangered mode. Although autonomous vehicles offer hope for animals on roads, how well can they be trusted when it comes to the lives of endangered beings? There have been instances where even the best-in-the-field of self driving cars have been confused. In this research work, we identify and overcome the failure spot of most animal Detection systems to present a fast, efficient, and reliable animal-vehicle collision avoidance framework - using YOLOv5.
Object Detection widely is used for detecting animals on the road but do we care to check if the data that we are training our object detection model on, is well grounded, valid and justifiable enough? Rarely.
What are some of the problems that autonomous vehicles face when it comes to animal detection on road?

- Lack of open source ‘animals-on-road’ image data to train the model on.
- Invalid and inaccurate image data used for training purposes. (See above picture example)
- Training on complex, heavy (and rather slow) deep learning architectures with lower detection processing speed.
Through this project we try to overcome the above mentioned drawbacks by proposing a well annotated custom dataset and a fully trained YOLOv5 model.
Reiterating, Image Data is instrumental in building the framework, we have crafted the image dataset pipeline such that no detail is missed out.
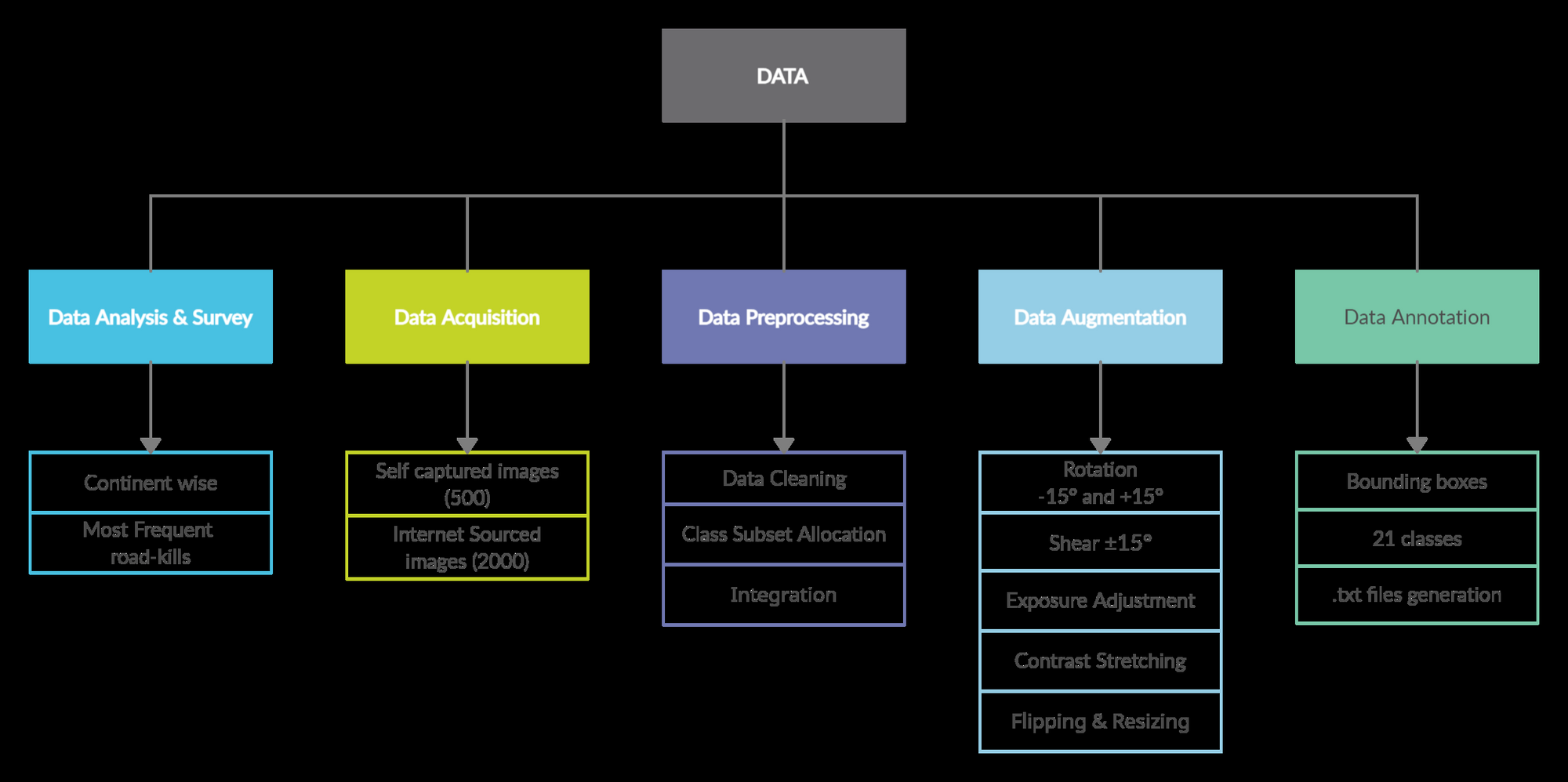
First Data Analysis is done based on published road ecology surveys across continents. Thus, we reach a conclusion of selecting 20 most common animal classes that are prone to road-kills in most of the continents.
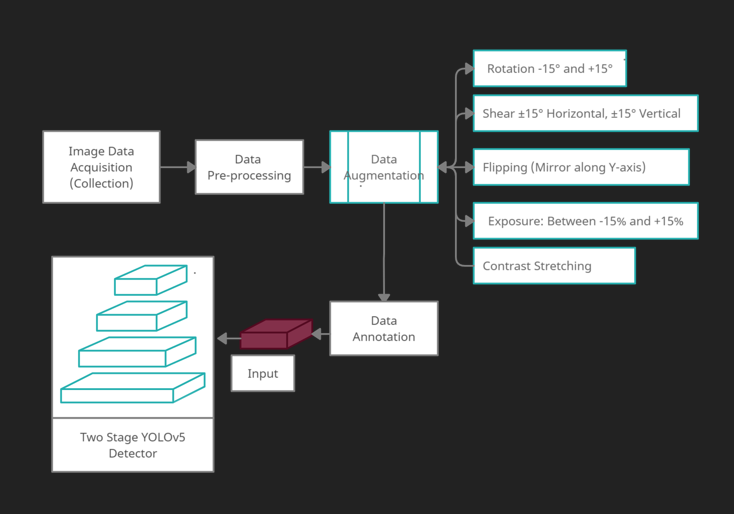
Data Acquisition
Most of the animals encountered on roads are not found in open-source public datasets like CIFAR-10 and MS-COCO, thus there is need for a new custom dataset. The dataset used to train our model consists of a homogeneous mixture of custom captured pictures and internet sourced public images. It contains 2500 images of animals on-road and by roadside, consisting of images pre-processed and augmented, picturing animals hopping, running, jumping, striding, crossing, moving etc., in different illumination intensities, captured while approached by vehicles in varying speeds, finally resized to 416 x 416 pixels to suit our YOLOv5 architecture.
The dataset is divided into 21 classes - Dog, Cat, Horse, Sheep, Pig, Cattle, Donkey, Camel, Elephant, Giraffe, Zebra, Bear, Kangaroo, Wild Buffalos, Deer Species, Fox, Monkey, Birds, Large-Wild-Cats, Lions, and animal-crossing- signboard. There are 20 animal-type classes, and 1 class is denoted for the ‘animal-crossing sign board’ display. It is important to identify an animal-crossing signboard, which can indicate the likelihood of animals crossing the road at that place, to warn the driver.
Data Augmentation
To enhance the experimental dataset, the acquired images were pre-processed and augmented. Often it is considered tough to implement augmentation strategies for object detection than for simple classification, as one must handle the intricacy of bounding boxes [19].
The following augmentations were performed on the data:
- Rotation: Between -15° and +15° - This rotates the image 15° clockwise and 15° anti-clockwise.
- Shear: ±15° Horizontal, ±15° Vertical - Shearing changes the shape and size of the image along x and y axis.
- Exposure: Between -15% and +15% – Increases the overall illumination i.e. brightness or darkness of the image.
- Flipping – Horizontal mirror reflections
- Contrast Stretching – Stretching the range of values of intensity in the image, to increase the dynamic range of the image.

Data Annotation
Data Annotation is a fundamental part of any Deep Learning project. The aim of Data Annotation is to set boundaries by defining bounding boxes in an image, within which the probability of the object being present is 100%. We define the bounding box values along with the class label. YOLOv5 in PyTorch reads the bounding box data in text file format (.txt), meaning all the object bounding boxes in one image would be combined and exported in one text file corresponding to the image.
Training YOLOv5
This completely annotated dataset is fed to the two-stage YOLOv5 detector. Ever since its inception, YOLO (You Only Look Once) architecture has been used extensively to train custom datasets for detection purposes due to its high accuracy and speed. The original YOLOv5 architecture -> https://github.com/ultralytics/yolov5
YOLO architecture sees the entire image during training and test time, so it implicitly encodes contextual information about classes as well as their appearance. The YOLOv5 architecture has three prominent parts. The backbone of the architecture is instrumental in detecting rich features from an input image. Further, the neck part of the architecture builds feature pyramids which in turn help in detecting same objects (animals) in different sizes and shapes. The head part is the final detector which uses anchor boxes techniques. Anchor box structure was introduced in YOLOv2, which tends to reduce training time and increases the accuracy of the network. However, a drawback of anchor boxes is that they cannot quickly adapt to unique and diverse dataset as in our case. To solve this, YOLOv5 integrates anchor box selection process by automatically learning the best anchor boxes for a dataset to use them during training over the dataset .
Biggest advantage of YOLOv5: detection processing speed of 140 frames/second
Assimilating, below is the flow of the entire system.
Results!!
To mathematically evaluate the model’s performance, and to compare it with previously published works, standard evaluation metrics were used – Precision, Recall, mAP. Recall = 91.46%, Precision = 85.62% Accuracy = 90.20%.
And… mAP = 91.27% !!
We consider mAP with IoU threshold > 0.5. Our model yields mAP score of 91.27%, which depicts a significant improvement compared to previous works.
And here’s how it performs!

For more details, visit research paper
Side Note: I had a great time building the entire dataset. From clicking pictures of animals on African roads to finding so many animals on Indian roads too! The most exciting part of the whole process - sitting overnight to train the model & observe performance metrics improve withith every small tuning!!