I like running. Although I’m not a fast runner, I like to think of myself as a long distance runner. Running can be difficult and overwhelming at times but once you get used to it, it becomes a routine. Wait, I am not talking about athletic running here. By the end of this piece you’ll know exactly what I’m talking about.
A couple of weeks ago, I participated in a Machine Learning Hackathon. I’d been studying Deep Learning, Statistics and revising Machine Learning concepts for months now and I felt something needed to be done. Kaggle competitions serve a great purpose, of course, but sometimes they can be confusing. I had been doing pilot projects too, but then their assessment was at stake. And something inside me kept telling me that it’s high time I stopped dwelling in theory and projects. High time to get assessed by experts. There. I grabbed the opportunity as I saw it and aimed at doing everything it asked me to do. I knew for sure that I wouldn’t win because this was a first (‘obviously’, I thought to myself). But that wasn’t something that could disappoint me. I am at a stage where learning, understanding and growing seem more important to me than anything else. With that in mind, I registered for it.
The days leading to the Hackathon saw me lazy, disappointed, unwilling and indolent as I was immensely nervous. This was my first Machine Learning specific Hackathon (well, I don’t count Kaggle competitions here) and although I was looking forward to it, I was scared. Nevertheless, I knew I had to show up and shoot the shot, for I cannot foster a statement and not do it myself.
On the first day, the organizing team sent in all the details of the Hackathon, along with a two paged guide explaining the problem statements and everything else that one would require to submit a solution. It was about Stock Prices prediction, but not the general kind. Honestly, I was worried when I read the tasks because I felt I was still a beginner (been a beginner for more than a year now). I read the tasks at least 7-8 times before confirming and settling down on their meaning. A conventional stock prices prediction algorithm wouldn’t work here because the data asked for more. It required something similar to a mutivariate time-series algorithm, I thought. I opened my notebook and started penning down a ‘how-to-do’ plan to go about with the tasks.
The first task was to predict stock prices based on the data they had provided. Pretty crisp and clear- train the model on the Training-set data and submit the Test-set predictions. Sounds easy, right? It sounded easy to me too, until I opened the Dataset.
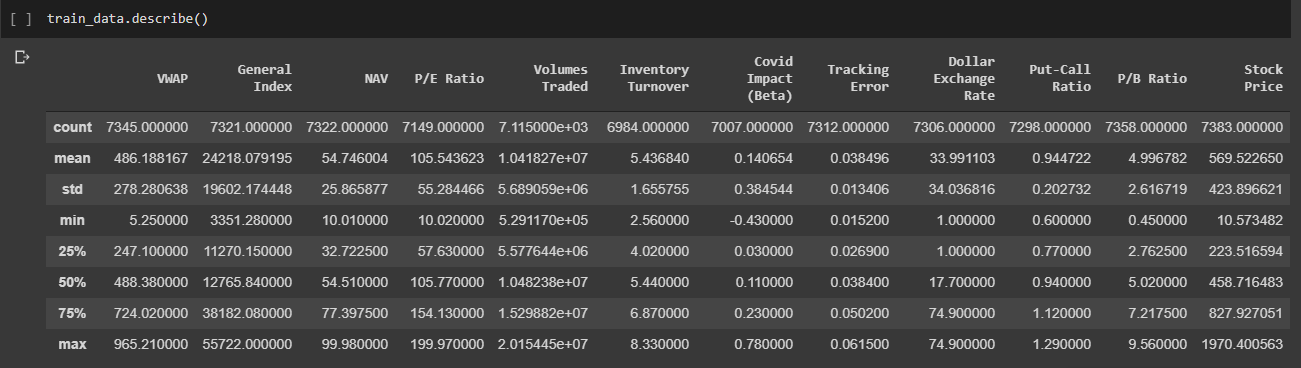
This is just a tiny summary of half the variables present that I generated using .describe().
I spent the first twelve hours understanding the data. I had literally zero idea about Stock Markets and the fancy jargon it brought along. So naturally, it was difficult to understand what the features meant, how they were related and how they finally contributed to the response (dependent) variable- here the stock price. Well, since Google did not have the answers to my silly questions, I texted one of my friends who had been doing stuff in this background. I threw at him my silly (the important) questions, asked him what these fancy words meant and how they were related in real life- all of this without showing him the real dataset. I think showing him the dataset would’ve made him biased towards particular variables and I needed a generic, unbiased understanding. In just 30-40 minutes he helped me understand meanings of all the variables. Now that the coffee with data was over, I started the exploring the data.
For Exploratory Data Analysis(EDA), I used pandas-profiling to generate a Profile Report of my data. This provides you with informative statistics about every feature in literally just a minute. It is one-line magical tool that always comes to the rescue. It reduces the time required to understand the data and increases your efficiency manifolds.

This is a pairplot generated using Seaborn library. Looking at this, it was clear that a Supervised Machine Learning Model had to be built, specifically a Regression model. But what type- I did not know because every feature was related to every other feature but the comprehending their relations was extremely difficult. Nothing made sense to me as the data was literally all over the place, clearly you can see.
After exploring and understanding the data, it was time to clean it!
The dataset was overwhelmingly big and unclean. Very dirty, I’d say. It required patient, comprehensive cleaning. Luckily, Exploratory Data Analysis (EDA) and Data Preprocessing were two sections I’d experimented a lot with. Understanding these methods and algorithms have helped me gain a good hold over data (at least I like to think so) and generalize a framework which comes handy while solving ML tasks.

I believe these steps are of paramount importance if you wish to get good models. After completing the cleaning process, I moved to model training part. I trained my data on various models, tuned hyper parameters, checked for model-wise different scores but still the models were not doing good. Finally I decided to settle down on Random Forests Model. I tuned the hyper parameters, performed boosting and bagging and decided to stop there. With this, the first task ended. I had predicted the prices for all the 3331 Test stock Indices with a mean R-squared value of 0.9674 (which is very flattering).
Now comes the real trouble. In the Second Task, I was provided with just one feature, the Put-Call-Ratio from 10th August to 15th August and I had to predict the Put-Call-Ratio for 16th August. This requires Time-Series Modelling (I couldn’t use my previous model as it had multiple features so univariate LSTM came to my rescue). Long Short Term Memory is a type of Recurrent Neural Networks that helps you deal with time-series data in a very good manner. Using the predicted Put-Call-Ratio for 16th August, I had to predict the corresponding stock prices of the respective stock Indices. But to my shock and surprise, this data had more missing values than I had expected. Another hour passed by, cleaning the new data!
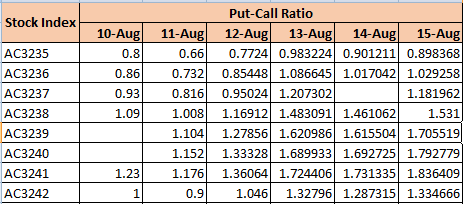
By the time I started task 2, I only had 4-5 hours left within which I had to finish my tasks, write a report and submit it. It was super challenging. I had to clean the data, use LSTM, perform trial and error with different parameters, choose scores and predict put-call-ratio and stock prices- all in five hours. When I was done, the output stock prices seemed extremely unreasonable. To someone like me, who had no idea and intention of diving in stock markets gibberish, if the prices seemed unreasonable, there surely was something that was messed up there, inside. I tried all that I could, and submitted the best of what I could get.
This is what it takes, it takes multiple takes. You cannot succeed in the very first go. You cannot get flattering accuracy scores. You cannot get the perfect model. You cannot get everything right till you mess it up and get it right again. There is no free lunch (more about it later). You have to get the perfect bias-variance trade off and it is not impossible. You have to generalize your model. You have to evaluate your model and critique the whole process before anyone else does.
An hour before the deadline I got an email from the organizers stating that they had extended the deadline. But I submitted my tasks on time. I stayed on the timeline I had prepared. Although I was a bit disappointed that the model wasn’t giving great accuracy, I was satisfied. I knew I’d given my best. The organizing team was extremely generous and co-operative. They literally called and told me that they will look at my files and give me an assessment report too. This is what I wanted and I was satisfied with that. I wanted to learn and improve and I was on the right track. Throughout the 48 hours, I don’t remember doing anything else. I felt very directed and there itself I knew that I liked doing this. I liked playing around with data, making analogies and framing rules with it.
Almost ten days after the deadline, they announced the results. And I seemed to have secured second place on their merit list. Although I couldn’t believe it, I was happy! I’d secured an A+ in the very first one I participated in. This has motivated me big time to keep doing what I’m doing.
Lessons (Key Takeaways)-
Prepare your timeline and maintain time. Maintain simplicity, put in extra efforts and do not forget to wear confidence, it always helps.
Coming back to running, this is what I call running. It all depends on how long we’re able to run. After more than a year and half of practicing Machine Learning, I landed here. There do come times when everything seems worthless, but we’ve to keep running. We’ve to keep running to reach these teeny-tiny milestones. And here, halting and savoring the aura around these milestones for a few seconds won’t do any harm. (Just a few seconds, not more not less) Because these milestones navigate you through the map, and help you reach your next milestones and ultimately your destination. And trust me, we all need this. So let’s keep running!